

Should the change from GPT-4 to GPT-5 raise or lower our expectations of AI? How big a jump is GPT-4 to GPT-5? Wrong questions. What is called “GPT-4” has changed over its existence. What we really need to know is how the overall performance of the best language models has changed over time. We want to know how the rate of change has varied, because it might give us hints as to the trillion-dollar question: what can we expect from LLMs in 3-5 years from now.
We need hard data. The traditional way to look at this is to graph how models have performed on a benchmark over time- typically what they score out of 100. The problem with this approach is that gains typically mean a lot more on tests as you get closer to the ceiling- 80% to 85% is not typically as big a deal as 90 to 95%. Of course, this might not even be true. We can imagine a dataset where 80% of questions have difficulty 4, 5% of questions have difficulty 7, and 15% have difficulty 8. Here, the biggest jump will be from 80 to 85%! The point is, for various reasons, skill at graded tests typically does not have a linear relationship with score on the test.
Fortunately, there is a way we can get data on language model skill in question answering over time. We can have users ask arbitrary questions and have two models compete against each other at random, each aiming to give the best answer. We can give the models what are called “Elo scores” based on their wins and loses. Elo scores allow one to estimate, given any two Elo scores, the probability of each player winning. This is the approach used by the LMSYS leaderboard.
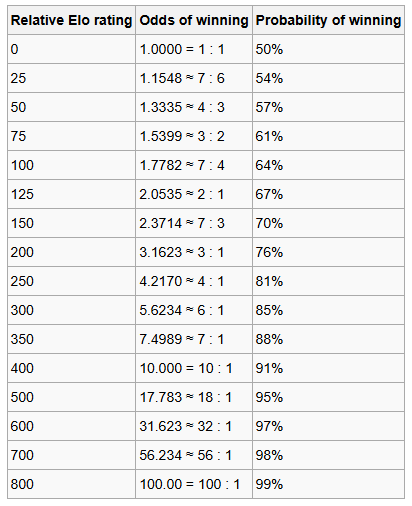
Now, some questions users ask just aren’t that difficult, and so comparing models on their responses is not going to reflect genuine differences in intelligence between models. Instead, it will only reflect differences in whim and personal taste as to how the response is framed. Hence, to better reflect differences in intelligence, we use the Elo scores from the hard questions only Subset.
All data is taken from here, except the first datapoint, which represents a semi-educated guess on my part. Each model represents the first model of that name, except where a specifier like 1106 preview is given. If you’re thinking of relying on this data in a serious context, I would suggest double-checking it, as cross-referencing the models with the release dates was a finicky business. For example, GPT-4O here represents gpt-4o-2024-05-13, which, naturally, I assume was released May 13, gemini-1.5-pro-002 appears to have been released in September 2024 etc., etc.
The LMSYS data is easily available, but for some reason, I’m the first person I know of to graph it over time recently, and in this format, including O1 and what came after it, though I have seen some older graphs:

What we see is that growth shot up as ChatGPT was first introduced, and presumably, as reinforcement learning through human feedback (RLHF) for LLMs was mastered. Then the score plateaus for a while, until reasoning models are introduced, whereupon it starts shooting up again. Overall, across 2.75 years, performance has increased by about 325 Elo points. There are pretty obviously three regimes of growth- any more structure than that would be speculative.
Note that the exclusion of models other than those made by Google and OpenAI will have slightly changed the frontier in a few places. However, it simplified the graphing greatly.
Interestingly, this graph is not particularly concordant with popular narratives about growth patterns in AI capabilities. GPT-5 shows up as a fairly robust improvement. The post-GPT-4 period, which subjectively “felt” like a time of reasonably fast growth, is shown to be far slower than the reasoning era.
It is natural to speculate that just as RLHF “ran out” and was followed by a slower growth regime, so too might reasoning as a driver of growth “run out”. A slowdown might be imminent if a new replacement for reasoning can’t be found.
Limitations
Naturally, things other than question answering are not directly assessed by this framework- e.g., longer-term tasks or agentic work. Also, a lot will depend on the model’s ability to “sell” its answer to humans.
This graph is obviously based on when models were released. We know the top companies have much better models than they’ve given the public access to. For example, both DeepMind and OpenAI have a model capable of getting a gold medal in the International Maths Olympiad. We must hope the ratio between released and unreleased model capability has held fairly constant over time.
I strongly suspect the LMArena test is starting to come to the end of its useful life. The ability of the average punter off the street to accurately judge differences in the quality of answers is probably being stretched to its limit in contests between the best models. If this is true, growth towards the end of the time range might be inaccurately compressed- perhaps the gaps between O1 and Gemini 2.5. Pro or Gemini 2.5. Pro and GPT-5 are bigger than they seem, but are shrunk by assessors preferring the wrong answers in cases where it is difficult for a non-expert to judge. There are ways the quality of assessors as well as the quality of models could be weighed, and I’d recommend LMSYS employ them.
Also, at least some questions in the “hard questions” subcategory are no longer truly hard for the frontier models. The following is an example of a “hard” question:
Level 6: Tell me how to make a hydroponic nutrient solution at home to grow lettuce with a precise amount of each nutrient
The test makers should probably introduce a really hard questions subcategory. Finally, I must note that as the pool of models tested has changed over time, the Elos are not perfectly commensurable.
For another attempt to graph LLM abilities in a way which is not constrained by score-out-of-100, see: https://metr.github.io/autonomy-evals-guide/gpt-5-report/

One thing to be cautious of here is that ELO is not designed to work for comparing different players across time. It works well for comparing a single player across time or multiple players at one moment, but not both at once. This can be seen pretty well with chess, where a 1500 ELO player today is a lot better than a 1500 ELO player a hundred years ago, because the techniques have improved over time.
Now, lmarena has tried to get around this. They technically use a slightly different model than ELO (though for this purpose I believe it’s functionally identical), but they also normalize against a model (mixtral-8x7b-instruct-v0.1, which has an ELO of 1114. For some reason it varies slightly instead of being constant though.). The normalizing process gets rid of some of the issues with measuring across time, but it’s not perfect and it still doesn’t mean nearly as much as one would like.
The other thing to take note of is that ELO is only a measure of relative performance. If a new model consistently does better than all the previous models, even if only 1% better on every question, it will have a much higher ELO. That’s fine for a realm like chess, but for something like AI you care a lot more about absolute performance than relative. I imagine that this played a large role in the second gain period, where reasoning models were able to be consistently better than non-reasoning models even if they didn’t actually improve that much at an absolute level. Meanwhile in the plateau period, models often made mistakes (and thus didn’t gain much ELO) but could still have large absolute gains when they weren’t making mistakes.
> I strongly suspect the LMArena test is starting to come to the end of its useful life.
This happened a while ago, I think. You don't need to completely exhaust the valuable signal to start overfitting - it's the default outcome once you use your measure as a target. And oh boy, are they ever.