
I’ve Solved Content Discovery! Conditions May Apply. Please Don’t Build the Torment Nexus.

Introduction
A few days ago, I proposed an experiment- let’s get AI to evaluate the essays in Scott Alexander’s review contest, and correlate AI’s evaluations with the actual scores. The rationale, inspired by Michael O. Church’s writing on using AI to find quality in publishing slush piles, was simple:
AI might be considerably better at spotting something people will love to read than producing it. This is intuitive. From chess to poetry I’m a lot better at grading genius than producing it. It’s simply an easier task.
If AI can be made to spot quality, or at least certain kinds of quality, this can ameliorate a problem. There’s a lot of great writing out there- from academia to blogs- that goes unread or has a very modest audience.
We could explore its capacity to spot quality by comparing its judgments with the ratings given in Scott’s book review contest.
Having run the experiment now I can confirm AI can predict Astral Codex Ten reader’s preferences over essays staggeringly well. The rank correlation, disattenuating for the very finite number of reviewers in the book contest, was probably about r=0.80. 0.76 without disattenuation is a figure we can be surer of, although the disattenuation figure I’ve given is if anything on the lower side. And that’s just with my ticky-tacky one-day vibe coded setup. The figure could surely be driven higher.
But r=0.76 and 0.8 are numbers that might not mean much to people. Here’s a concrete illustration. There were 5 finalists, in our sample. AI put 4/5 in the top 5, out of 57.
An AI recommender system is thus possible, and in the long run probably inevitable. Chris Best, hint hint. The trick will be making sure that it is seen as one way that writing can come to public attention. It must not be the only channel, lest the biases of the machine lead us to delve into the rich tapestry of an AI monoculture. You’re right to push back on that!
The stripped-down Haiku only version of my methodology is eminently affordable, at a cost of about 5-10 cents an essay. Or 50 cents an essay if you want the deluxe Opus+Haiku treatment. If you ration that- you can submit one essay to the digital slush-pile per week- my back of the envelope calculations say it is affordable rolled out across Substack.
Heck, I’m thinking of offering it as a service myself. Sound off in the comments if you’re interested.
Don’t build the torment nexus
There’s danger here I’ve already alluded to. There are two problems with relying on LLM discovery exclusively. The first is that it doesn’t predict what the crowd thinks perfectly, and its errors aren’t random or uncorrelated. The second is that even if it did predict what the crowd thought perfectly, the crowd frankly has atrocious taste sometimes. This essay is about predicting the ground truth of what people like, but have you seen some of the garbage people like? Sheeesh. We wouldn’t want to lock in existing prejudices under the category of: “but the machine says its right”.
So, using AI as a sole method of content discovery would be building the torment nexus. I am telling you not to build the torment nexus.

A word on “quality”. We use it in this essay to mean that which is popularly regarded as of high quality. We contrast it sometimes with “true quality”- the real aesthetic and intellectual value of a thing. True quality might seem completely beyond science, but later on I wil qualify that inaccessibility.
Results:
The interval censored rank correlation between the average of Haiku and Opus’s ranks and Scott’s readers ranks was 0.76, N=57, MLE estimation. We couldn’t just use straight correlation or rank correlation because we only have interval data for some of the essays, as I’ll describe in the section on subjects.
We need to disattenuate the relationship because human interrater reliability is quite low. This means that if a much larger number of reviewers had read through the contest essays, the scores might have been somewhat different- and the machine shouldn’t be penalised for not predicting statistical noise. I performed a back-of-the-envelope disattenuation, based on a figure that’s floating around suggesting the average number of reviewers was 32, and based on prior studies that find a reliability for this sort of thing (e.g. grant review, book review) of 0.5. This suggested a true relationship of 0.80- so not a massive change. It probably understates the disattenuation slightly because variance in the number of reviewers around a 32 average would push it down, and I suspect human reliability of 0.5 is a bit high here. I did not disattenuate for AI’s unreliability, because although theoretically you could run the model an unlimited number of times, in practice it wouldn’t be cost effective- so disattenuation would give a dishonest appraisal of the strength of the method. However, if we partially disattenuate it by imagining running 50 rounds instead of ten we add an edge of only about r=0.01.
One notable result as mentioned earlier is that 4/5 humans rated in the top 5 were in the top 5 according to our ensemble, although one was demoted to 19. This strong relationship is all the more staggering when we consider that people get their friends to vote for them in Astral Codex Ten contests (even though they’re not supposed to). Why was one of the finalists in 19th? I have a speculation here. The essay was on phase I clinical trials. Scott is a doctor, the blog was originally focused heavily on psychiatry, and many of his readers have a medical background or are otherwise interested.
I ran some formal measures of writing features. This was extremely exploratory and my concern was simply to find lines for further research. As such the problems of running numerous underpowered comparisons with a small N and a somewhat odd sample apply- so take these with a salt mine, and only as possibilities to investigate in further studies.
A bevy of formal measures of prose quality were run- sentence length, readability indexes and lexical diversity. Almost all came back null- no effect on humans, robots or the gap between them. Word frequency was slightly rewarded by AI and causal connectives (“therefore”, “because”) were slightly punished. Surface measures of controversial topics based on bags of words didn’t find anything except that humans and AI alike seemed somewhat averse to sex, but I would very much prefer human or AI manual coding with a larger sample here. There was no difference in “moral foundations” related language, with some limited evidence that AI and humans alike distrusted moralistic language. Being a Haidt doubter, I hasten to add that I used the moral foundations language test purely to detect moralism general - not Haidt’s five pillars which I am quite sceptical of.
Early results suggested that AI might be less impressed by emotion terms than humans. It’s not that it responds negatively- if anything it responds mildly positively- but humans seem to like them more. I do think there’s an interesting question here. If humans are all too easily impressed by vivid emotional palettes without restraint, maybe we shouldn’t be making AI validate this. On the other hand, maybe we’re already too scared of emotion, maybe we’re too restrained, and maybe AI, with its fear of a certain kind of cringe, could be amplifying this. But again, this is very preliminary and a larger N and pre-registered testing is needed.
Scott’s readers who submitted are, I think, better writers than average on a platform like Substack. If I had to guess I’d say it’s not close- outside a few walled gardens Susbtack is full of slop, LinkedIn adjacent rubbish, dreary polemic, and all the usual vices. Hence our sample probably included a degree of variance reduction. Without this reduction, the relationship between the predictor and the predicted would almost certainly be substantially larger, because that’s how variance reduction works.
There is a relatively small possibility of training set contamination. AI and scraping couldn’t access the essays- I had to get them manually for the LLM feeding them into the API. Even if they were available, I doubt they would be remembered with much accuracy after a handful of occurrences. Predict Opus, which I describe in the appendix, did not refer to contest results in its reasoning, although take that with the entire 53,598,800 metric tonnes of salt produced by China in 2022. The next step is to run the experiment on Scott’s ongoing book review contest, completely ruling out training set contamination as the scores aren’t publicly available or even complete yet.
What this means in practice:
The obvious implication is a method of writer discovery. Authors can submit essays to a central repository and the repository can score them against each other. In doing so we can scoop cream that would otherwise remain invisible. The essay of a poor schmuck on Substack with 37 subscribers is unlikely to be read no matter how good they are. Scott’s own contest is evidence of this- many of its winners and finalists have modest or no audiences. If a recommender ensemble says an essay is good- in the top 5, 10 or 20 percent submitted, the essay might get a chance. This could either be a commercial service, a volunteer operation, or an add-on to websites like Substack. If anything like our results is replicable generally, frontier models have more than enough accuracy to meet this need.
You know who could try this? Lesswrong. They get about 10 submissions a day, and their current quality ratings are contaminated by the Matthew effect: plausibly a small number of upvotes or downvotes early on can lead to a cascade or to people ignoring an article. There’s also an issue of username followings. An LLM recommendation feed would be a nice addition to the website.
This all might seem like an indulgence. Finally! Meritocracy for writers [conditions apply]. And this means exactly what for 99.99% of the human race? But good writing is important because writing is how society reflects. I don’t just mean that in a spiritual or Socratic sense, but practically. Consider, for example, rolling out a similar system in, say, materials science, policy analysis or pharmacology to rank important new papers that academics should read.
Of course, I will repeat my caveat again. True quality is not fully captured by this system, and overreliance on it would produce civilizational blind spots. There is no easy ground truth for true quality, as opposed to mere popular preference. You’d better hope those materials scientists aren’t using AI as their exclusive basis on which to decide what to read, or else things might go badly. From materials science to literature, we need people fossicking around the unpopular, the weird, the stuff most people wouldn’t like even if they gave it a chance.
But the even bigger point here is writer discovery. We’re judging single essays. Say instead that we judged 10 essays per entrant, our writer discovery capacity would go up even more. We might even be able to nearly-reliably discriminate between someone in the 90th percentile and the 99th percentile which would be an astonishing result. Caveat- because the model’s errors will be correlated, increasing the sample from 1 to 10 might have less effect than a naive model would suggest.
There’s also another avenue here that I won’t go down in this particular essay- targeted recommendations. These could be either based on listed interests and personal features, or on a record of what you have liked previously- judged against possible further reading by an LLM instead of a relatively dumb algorithm. The usual additional concern about echo chambers applies here.
Methodology:
Basic idea:
The basic idea was to get Haiku to judge two entries against each other and assign a score to each. This dealt with two problems at once. Our initial approach was just to pair essays against each other and extract a forced choice, but this discarded too much information, and first entry bias was too strong a factor. On the other hand, pure scoring “on the merits”- where Haiku assigns a number without a comparator runs into the problem that the number isn’t grounded. What’s the standard? The best essays ever written? A year nine class? The overall score for each essay was its mean score across all comparisons.
Having run Haiku and gotten good results, I then thought “what if we bring in Opus”. Opus also got a good match, so my next thought was “what if we average Opus’s score and Haiku’s”. They’re two quite different models, so the personality quirks might average out. My pet theory was Haiku will capture surface quality features correlating with the inattentive or not so perspicacious section of the crowd, whereas Opus will model those with deeper insight. As we’ll see, this hypothesis wasn’t clearly true, but it was in the vicinity of some interesting results.
Averaging Opus and Haiku’s scores greatly increased the correlation. I was surprised by the degree to which they seemed to complement each other’s weaknesses.
I considered predicting via a regression model instead of simple averaging, but at that point the tweaks start to look like abusing researcher degrees of freedom to get a bigger number, so I decided to leave it till next time when I’ll pre-register it.
Prompt
The prompt went like this:
You are a judge in a writing contest. You will be shown two essays and asked to score each one.
Score each essay on a scale of 0-10, where 5 represents a typical, competent contest submission — neither impressive nor poor. Scores below 5 are for essays that fall short of typical contest quality in some way. Scores above 5 are for essays that exceed it. Scores of 8 or above should be rare and reserved for essays that genuinely surprised you. Scores of 2 or below should likewise be rare, reserved for essays with serious problems.
You must use the full range. In a large contest, some essays will score 2 or below and some will score 8 or above. Clustering your scores between 5 and 7 is a scoring error.
Reply in this exact format and no other:
Essay A: [score]
Essay B: [score]
Pairings
Each essay was scored in 10 matches. No entry was matched against the same rival more than once. In exactly five of its matches, it was presented first, and in five second. Within these constraints, pairings were random. This was repeated with Opus after results were derived for Haiku, using the same pairings.
Subjects
Our initial plan was simple. Include in the analysis only essays that were:
A) Under 8000 words
B) Where I had at least ordinal information on rank for (this last criterion excluded Red Means No, which is an honourable mention but not because of its score).
C) Which haven’t been subsequently withdrawn (an entry on the Ukraine war was withdrawn after becoming one of the winners)
Of the entries that weren’t in the top 50, a HM, a finalist or a winner, I picked 20 at random.
So all up I had:
No winners (all were over 8000 words or excluded because the author has since withdrawn the essay)
5 Finalists. We knew these were finalists, but not their order, giving them a rank interval of 1-5 in our sample. To clarify that means if we knew their average score they would be somewhere in this range within our sample - not across all entries in the contest.
2 Honourable mentions. We knew these were honourable mentions, and thus below finalists and above the rest, but not their order, giving them a rank interval of 6-7 in our sample.
All members of the top 50 under 8000 words (31 in total- or so we thought).
20 Items from below the top 50. We knew only that they were below all the above groups, giving them a rank interval in our sample of 38-57.
The big kerfuffle
Then the big kerfuffle happened.
I ran the initial analysis and got reasonably good results.
Just as I was getting ready to publish, I, in a moment of levity, asked Opus to defend its low score of Zone of Interest. It opened the document and discovered what we had labelled Zone of Interest was 4 essays glued together. We’d hit an extraction bug.
So, we duly panicked, I asked Opus to find all the essays like this, if there were any others. It turned out, mirabilia dictu all our outliers were in this category as well as a bunch of other entries that weren’t outliers, though from memory they were somewhat off in scoring. This makes sense- AI can’t evaluate an essay if it’s only got a glued together monster which that essay is part of. There were 14 in total, including 5 that were merely truncated.
After we removed all the managed essays were left with N=43 and a much higher correlation.
But then I thought it over. My conscience was spurred on by my ever-earnest lab assistant Claude. I decided: 1) so long as we reported it honestly, we could probably get away with N=43- because the attrition didn’t happen in any way that would create bias- 2) However it would be cleaner to run the experiment again for these essays. We did, and Claude also found an additional 2 essays under our 8000-word cap, bringing us to N=59. We reran the essays we didn’t have proper data for, including contests against them by the other uncontaminated essays. During rerunning we found that we’d missed x2 essays that were contaminated. Rather than rerun again, we just cut them. They are essentially randomly selected so there’s no bias I can see, and I couldn’t keep paying for runs.
If there are any remaining truncated pieces or chimeras in the sample- which I wouldn’t bet my life against at this point - we can rest easy in the knowledge that they are noise and so in expectation they would have lowered, not increased accuracy.
Directions for future research:
As noted above, I do not consider data contamination a likely cause of this result, but the next step needs to be to rerun the experiment on the ongoing book review to predict the results in advance, giving peace of mind. After that’s done, we can address the following topics.
Is this all an artifact of some regrettable pattern?
Is AI picking essays with undesirable qualities like not saying much?
We can’t know, but I did run one preliminary check. I identified five forms of authorial courage (Claude contributed here):
Intellectual bet - the significance and surprisingness of the claim being made, regardless of whether it is well or poorly defended. “I have a proof of P=NP” would max out this rating. Something like George’s Rey’s claim in meta-atheism that almost no one really believes in God would be an 8 or 9.
Self-exposure - confession of dangerous or privacy damaging facts “I have committed many sex crimes” would max out this facet”, “I have been a victim of a sex crime” would be an 8 or 9.
Anti-mainstream stance - the extent to which the essay goes against the mainstream. “Our soldiers deserve to die horribly in wars” would max out this scale, “We should abolish private property” would be an 8 or 9.
Anti-rationalist/ACX stance, the degree to which the essay goes against the values of the readership that reviewed it. “Scott Alexander should be executed” would max out this scale, “AI risk is overhyped nonsense” would be an 8 or 9.
Formal risk- the degree to which the essay goes beyond or subverts normal conventions for writing a review essay was our final facet. “My essay is in Lojban Sestinas” would max out this scale, “My essay is a short story instead” would be an 8 or 9.
The bravest possible essay then is something like:
How committing my numerous sex crimes allowed me to generate this proof of P=NP, and why the pigs who arrested me should be boiled alive in oil, a verse essay in Lojban sestinas.
Which goes to show that bravery=good is not a safe assumption(1).
Haiku is Haiku, Opus is Opus. Pred Opus is prediction Opus which we will talk about in the appendix.
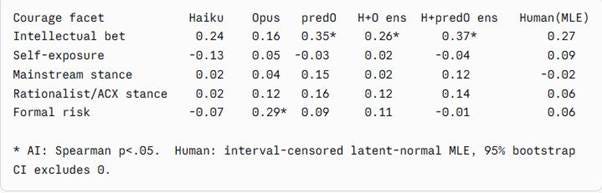
Essentially there is no signal here except that there does seem to be a genuine tendency for everyone - man and machine - to prefer bigger intellectual bets; but only by a little bit. This is, I think, healthy. We want to reward big claims, but not too much, so as to avoid encouraging wild speculation and contrarianism. These results suggest that AI is not obviously quashing originality.
There was some signal in variance- the swingyness depending on intellectual courage. Humans scores tended to be a bit more extreme as intellectual bet increased. AI trended in that direction, but not as strongly. However, the difference wasn’t significant.
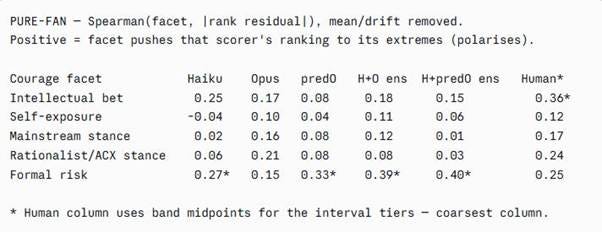
The big standout to my gaze is formal risk. AI was substantially swingier as formal risk expanded- judging formally risky essays quite a bit more harshly or generously depending, presumably, on whether it saw the gamble as paying off. There was a non-significant tendency of humans in the same direction and the difference between AI and humans here was non-significant whichever comparison you look at.
But what about intellectual demandingness, as opposed to courage? This isn’t the same as intellectual bet, though it is correlated with it. Something that says almost nothing can be very hard to follow. Something that says a lot can be easy to follow. Being hard to follow is not, I would argue a vice if it is intrinsic to the ideas and concepts one is working with. It is not intrinsically a virtue either.
I had Sonnet rate pieces for how intellectually demanding they were out of 100. The main result was that nothing broke above the low fifties- Sonnet is a confident bugger and clearly has tabs on itself. The only robust result in the correlations was that the bottom quartile of intellectual demandingness rated poorly with AI and humans alike. So, at first glance AI isn’t dinging things for being on difficult topics or written in a difficult way.
Further research on potentially dangerous patterns in AI scoring of writing will have to go much further than this, of course.
As I discuss in an appendix Haiku and Opus didn’t have a preference for stereotypically masculine or feminine content, but predict Opus, which we will introduce later, preferred stereotypically masculine content.
Trying to get an even higher correlation
Opus and Haiku, despite oue explicit instruction, did not use the full range- especially Opus. Fixing this could substantially increase power.
I think one promising idea is to score a whole batch - say 10, at once. Why? Because scoring a batch of ten gives a stronger idea of the variance in the population than one comparator and probably gives our command to use the full range more force.
There are many possible directions for prompts. For example, we could try having the model generate sub scores for facets like “logic”, “originality” and “prose”. These could either be used to mechanically calculate an overall score, or the model could be asked to ‘consider’ these sub scores in giving a total. Alternatively the scores could be entered as predictors into a regression model.
A might have identifiable prejudices. Preliminary evidence suggested it didn’t like sex related content, particularly if it came close to harm [it hated Red-means-no orgies when we looked at it, though it wasn’t included in the final analysis because we had no information on its rank]. It may have been leary of political content- especially Haiku. A proper flagging system- how much is this essay about sex or politics, followed by a score adjustment, could have an impact on predictive power.
Growing the judging ensemble to include other models (perhaps ChatGPT 5.5 or Gemini) is also attractive. Opus was a bit less accurate than Haiku, so bigger needn’t mean better here.
I strongly suspect with:
1. Better prompts,
2. Better ensembles using a regression formula,
3. Better gating to ensembles depending on essay content,
4. Greater variation in the quality of essays by using a more quality diverse population
And various other tweaks, we could get the disattenuated correlation to close to 0.9 or maybe even reach it. But we’re already at 0.8 or so I would say “make r biggerer” is not our priority.
The more interesting direction, trying to get at true quality
A portion of the difference in score probably reflects better judgment than the Astral Codex Ten readership. There are ways we could investigate this. For example, examine correlation with the judgments of a group of 10-20 people who we, for theoretical reasons, think have better judgment in aggregate that Astral Codex Ten readers in aggregate. One simple way to bootstrap this is to find a group of people who Astral Codex Ten readers would agree have better collective judgment than ACT readers.
There’s an analogy here to ideal advisor subjectivist theories in philosophical aesthetics and metaethics or the related idea rationalists call coherent-extrapolated volition. If you and I both agree after reflection that Bob is a better judge of merit than me, and your ratings correlated better with Bob’s than mine then there’s a sense in which, by both our lights, you’re a better judge of merit. Similarly, take some gathering of the heroes of ACT. Individuals might not be so self-deprecating as to say that they are worse at judging than any of those heroes, but they certainly agree that a large group in which they are but one member, made up of randoms from the commentariat will be worse than this collection of the heroes of that commentariat.
This, I think, is the real game. Not trying to match the crowd but outdo it. The lack of obvious ground-truth labels will require ingenuity, but there’s quite a few leads here if you know where to look. I’ve described one strategy above and I have a few more up my sleeve that I’ll save for later essays.
Of the approximately 36% of the variance our ensemble doesn’t get, some of it represents a superior perception of true-quality by the machine than Astral codex reviewers. True quality here is relative to some operationalisation of true quality like the coherent-extrapolated-volition methodology above. Conversely, some of the missed variance represents superior true quality perception by the Astral Codex Ten crowd. Finally, some of it represents a legitimate difference of goal. The ideal Astral Codex Ten review essay is not the ideal essay simplicter. Breaking down the size of each factor is an important project.
Of course, the constructivist methodology I outlined hits limits. Since this is in some sense an essay about Astral Codex Ten, let me make a strained analogy to the Talmud. We’ve probably all heard by now that it is written that the Torah, if arranged in the right order, contains the secrets of the universe and can raise the dead. If that is correct, the Torah is the highest quality document in the world in some sense, but we’re all too sinful to grasp the true ordering. There’s a higher form of true, true quality within it beyond the reach of any language model or feasible human-self modification. Hence, while we can get at quality and maybe even “true quality” by some constructivist measure, we cannot get true true quality. Considerably less extreme and Kabbalistic examples are possible and have existed at many times and places in history. An exercise for the reader. Perhaps the constructivist methodology can even cover this worry, through ever more idealised and rarefied agents in ever more ideal speech situation. Perhaps True-infinity quality for an agent is just what they’d accept after all idealisations of their judgment that they themselves would accept, in the manner of coherent-extrapolated-volition or idealising subjectivism. Or perhaps a Platonic truth of aesthetic and intellectual value lies even beyond this.
But I’m inclined to think it is not in heaven.
Machine aesthetics- a case study
I came up with a theory about the difference between Opus and Haiku. It is incredibly self-serving, but here goes. My own review happened to be one of the twenty in the sample picked at random from those that did not reach the Top 50. Opus quite liked it, putting it just within the top third. Haiku hated it, putting it at the edge of the bottom quarter. But this made me reflect. Consider the difference in scores between Haiku and Opus. Perhaps the difference represents the gap between a quick, shallow level read and a deeper more attentive read.
Hence:
(Opus rank minus Haiku rank) might be an indicator of hidden quality, the value of a thing which is only apparent on a deeper read. We would expect both models to correlate with different aspects of the crowd- the shallower readers and the deeper readers. Perhaps in the delta from the shallower to the deeper we have a potential indicator of true quality by effectively partialling out the less attentive and perspicacious portion of the crowd.
Was this right? No, but I was close. Formal bravery - writing something unusual with regard to the review essay genre - correlated with differences in Opus-Haiku verdicts 0.45. Opus likes fucking around with form- unusual subjects, unusual structures etc, and Haiku doesn’t. Moreover, we introduced an additional concept “conceit weirdness”. Conceit weirdness includes things like reviewing a religion almost as if it were a consumer product, or the soul of a friend. We had it rated by Sonnet and it correlated 0.55 with the gap between the score of Opus and Haiku. When we took the two together, conceit weirdness and formal bravery and regressed them on the score difference the multiple r was 0.62. Disattenuating for the unreliability of Opus and Haiku- the part of the gap that isn’t just noise was explained r=0.68.
In other words, you can make a very, very good guess about the difference in Opus and Haiku’s opinion simply by knowing how unusual the conceit is, and how obliquely the author approaches the form. This is very probably why Opus had a much higher opinion of my essay- a review of a living friend’s soul- than Haiku.
This is arguably a classic slobs and snobs / middlebrow - highbrow clash. Am I claiming Haiku is the guy in the art gallery saying his child could paint a Rothko? No, but I’m not not claiming it either. The most plausible explanation is that Opus understands formal play better. The second most plausible is that because Opus has a larger training set and a better memory of it, it’s sense of novelty is harder to trigger, but it rewards novelty when it sees it. In other words what is driving the gap, could be comprehension and/or the jaded taste of experience seeking something new. A third hypothesis, suggested to me by Claude, is that it could be RLHF differences. Opus, being the larger model and thus more capable of assessing risk, is encouraged to make bolder choices, whereas Haiku, being less intelligent, is encouraged to play it safe, lest it trip something up. Consider how we tell children to be far more cautious than adults, because developed judgment keeps adults safer.
But our picture so far is a bit misleading. Haiku has basically no dislike of formal bravery - the correlation was non-significant and close to zero. Rather it’s that Opus likes it. Moreover, the crowd is closer to Haiku on this than Opus. However, when it comes to unusual conceits, the public is on Opus’s side-moderately. The most interesting question to me then is the hardest. Is Opus right to like formal bravery and unusual conceits?
Here’s the top ten essays by Opus minus Haiku rank [rank reverse coded]:
US Census
The Delusion Of Infinite Economic Growth
The Soul Of An Anti-Woke Intellectual
11 Poetic Forms
Arbitraging Several Dozen Online Casinos
Zermelo-Fraenkel Set Theory
Toki Pona
The Drum Major Instinct
Call Of Duty’s Campaigns
The Emperor of All Maladies
The following list is essays that rated substantially higher according to AI than human scorers and were in the top half. I’ve put it here in case someone reading this piece wrote one of them, and might find a bit of validation in seeing it on the list:
My Childhood Television Set [AI loves this essay]
Detective Pikachu
Gacha Games
Princess Mononoke
The Witness
Two Years of Parenthood
North Korea
Scientific Peer Review
Toki Pona
Shout out to Judaism(2) - written by a close friend of mine. In the contest it came in just below the honourable mentions- AI thinks should have been a finalist.
Appendix: An additional experiment predicting the contest results better but at what cost??!?
But what if we told a model to predict who was going to win the Astral Ten Codex contest specifically instead of just assess quality?
Call that model Opus-Predictor, because it predicts contest winners.
Turns out Opus-Predictor correlates more strongly with the results- censored interval correlation of 0.82- than our original Opus model. Is this signficiant- original Opus on its own vs predictor? Unfortunately, that’s a very good question. The long at the short of it is that it depends on analysis, which is part of why I’m going to ask Scott for the original vote tallies for all essays so we don’t have to fuss around with censored rank interval correlations, MLE and other difficult, fancyfooted statistics and missing files. Our current best analysis is p=0.1. The phrase “current best analysis” should tell you how seriously to take that. Disattenuation bumps up Opus-Predictor to about r=0.86. The figure itself is very strong, about as good a figure as I have ever heard for anything remotely like the experiment we have done. However I note again, I would trust this much more if we had the scores and not MLE on censored rank intervals.
Suppose there were a hypothetical essay rated by tens of thousands of raters. You can’t read the essay but need to guess its score. You have a choice, you can either use Opus-predicts or rely on the judgment of some randomly selected raters. The equality point is somewhat sensitive to assumptions, but it’s around 8.
Unlike the other models we asked it to reason before scoring. My rationale was that while quality is an impression the model could form as a reaction- an instinctive synthesis- working out competition results was better handled through reasoning. Here was the prompt:
You are predicting the results of the Astral Codex Ten (ACX) Non-Book Review Contest, in which readers of Scott Alexander’s blog read entries and vote for their favorites. You will be shown two entries. Your job is NOT to judge their quality in the abstract, but to predict how each will actually perform with the ACX readership. For each entry, first write a short assessment (about 120 words) of its likely reception — what about it will appeal to or alienate this particular audience (ACX / rationalist-adjacent readers), and how that is likely to translate into votes. Do not mention any numbers or scores in the assessments. Then assign each a score from 0-10 representing its predicted standing in the contest: 10 = a likely winner or top finisher, 5 = a middle-of-the-pack entry, 0 = likely to finish near the bottom. Use the full range. Then, after the line ===FINAL SCORES===, give the two scores and nothing else. Reply in exactly this format:
Essay A assessment: <your assessment>
Essay B assessment: <your assessment>
===FINAL SCORES===
Essay A: [score]
Essay B: [score]
There’s some evidence, like I speculated in my prior article, that Opus-Predictor over psychologises the crowd it’s predicting. I had Sonnet code articles as stereotypically masculine or feminine. Opus-contest-predictor’s scores correlated around ~0.35 with how masculine/feminine an essay was, whereas the actual rank had nothing to do with this (Astral Codex Ten readers aren’t as stereotypically masculine as you might think- will wonders ever cease?). Opus from the previous experiment, merely asked to estimate quality, did not fall into this trap, it had no stereotypical gender content preference, or one too small to be detected with N=57. This work on gender is very preliminary, vulnerable to post-hoc multiple comparision, and should be taken as a proposal for future research rather than a statement about how things are.
My strong suspicion, although I cannot prove it without further analysis, is that Opus-contest-predictor is better at predicting the results of the contest (unsurprising) but worse at giving a score that reflects what an essay truly deserves. This is important, I think, because it reframes our 0.76, (0.8 disattenuated for unreliability) result from earlier. The result is high, and that is a proof of concept, but I am not even sure we particularly want the correlation to be higher. What we want is to use the scores as one indicator of underlying quality, and develop approaches that track multiple quality indicators, seeking the latent variable.
Prior literature
Like many researchers I investigated the prior literature in a systematic way only after I’d basically written everything else, but there are number of authors who have priority who I must acknowledge.
Comparative judgement in educational assessment. - I paired up essays to have them scored, to deal with LLM biases that creep in when a thing is assessed without an anchor. Turns out this was first extensively trialled in human education, a key text here is apparently: Alastair Pollitt’s “The method of adaptive comparative judgement”. Also see Thurstone’s law of comparative judgment and the Bradley-Terry model, which, having discovered them five minutes ago, seem super cool. Essentially, they’re statistical attempts to turn the number of times A is chosen over B into a score for A and B’s quality. We ultimately went in a slightly different direction, with scores in addition to comparisons.
Automated essay scoring - starts with Ellis Page’s Project Essay Grade (1966). Classic critiques e.g. by Perelman make the point that it can be gamed terribly. This is because automated graders thus far work on very surface level features- presence of key words, length, automated spelling and grammar checking, sentence length etc. I should state, for the record, that I reject on fundamental grounds AI marking. People who are learning to write deserve to be read. Writing essay after essay that no one will read is an indignity, even if the grader is as good as a good human- and rule-based stuff never will be. The newer LLM based stuff seems a bit better, albeit it doesn’t escape my ethical objection, but most authors haven’t been able to get strong results, or at least few have gotten results as strong as ours. See Li et al. (2025) for discussion. Why are they struggling? Probably 1) they’re trying to match a single marker’s score, but these are far nosier than what we’re looking at and 2) they’re not marking essays against each other, but rather on their own.
Automated peer review - Still in early stages but starting to roll out in actual trials now. See Yuan, Liu & Neubig (2022), an early attempt that concluded the tech wasn’t ready for high-stakes use; Liang et al. (2024), the first large-scale evaluation of GPT-4 feedback against human reviewers; and Thakkar et al. (2026), a randomized controlled deployment at ICLR 2025.
Seriously, don’t build the torment nexus
Don’t.
A bleg
It cost me quite a lot to run this experiment. The actual core API calls were not that expensive, but having to rerun stuff, vibe code etc. and thus buy extra usage cost me quite a bit, and all up it cost me about ~250 Australian. It’s certainly not going to push me into penury, but if you’ve ever thought about signing up as a paid reader, it’d be a lovely thing to do.
Footnotes
(1) Don’t give me any of that Aristotlean unity of the virtues this isn’t real bravery it’s just sparkling foolhardiness rubbish, please.
(2) Did you know I’m not Jewish, despite numerous of my friends being Jewish and a habit of riffing on Kabbalah and the Talmud with some frequency? I mention this because I often worry I am stealing Jewish valour.

Speaking as someone overall deeply opposed to LLMs -- the sort of person who'd ban them beyond a spring-2022-level size limit given the chance -- I nonetheless think that, while we're stuck with them, this project seems a brilliant use of their talents. Like, I don't think the potential societal goods of LLMs could ever justify the urgent harms they do, but they're great at sifting through large quantities of data, and apparently, somehow, that even includes pattern-recognition about good writing. Cool!
If LLMs have showed this level of talent at sorting like Astral Star Codex readers -- whose finalist entries tend to be excellent reading -- we should let 'em use that talent to find good unknown writers and bring them to the attention of would-be interested readers. Because we sure don't have a good framework for that sort of treasure-sifting at the moment. And we should.
I'm not a huge fan of the whole "fucking around with the form" thing. It kinda seems like it's just a method to hijack the contest to get more exposure for something you wanted to write anyway. Perhaps that's a lowbrow prole opinion, but lowbrow proles keep society running, so have a little respect.
I think this project could have a ton of merit though, as long as people don't abuse it to set up one particular standard as some kind of "objectively correct" ranking system. I think having different AIs with subtly different standards is a great way to do this, actually. I could mostly listen to the Haiku ratings but also occasionally check the top Opus ratings to see if there's something great I would have overlooked. Sort of like fractional distillation of different categories of writing out of one gigantic disorganized slush pile.